Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving,
where timely detection of unexpected activities is essential.
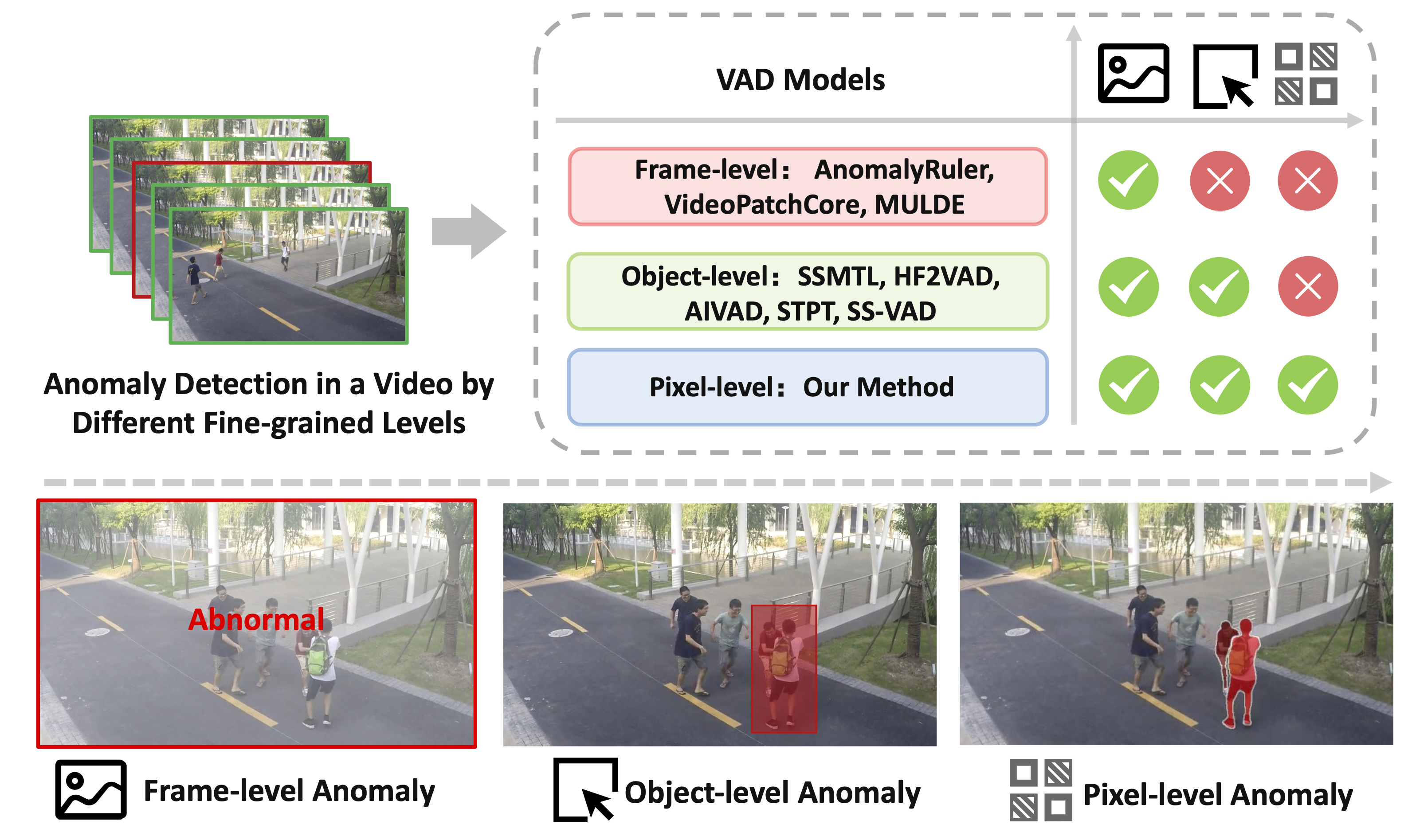
Albeit existing methods have primarily focused on detecting anomalous objects in videos—either by identifying anomalous frames or objects—they often neglect finer-grained analysis,
such as anomalous pixels, which limits their ability to capture a broader range of anomalies.
To address this challenge, we propose an innovative VAD framework called Track Any Object (TAO),
which introduces a Granular Video Anomaly Detection Framework that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework.
Unlike methods that assign anomaly scores to every pixel at each moment, our approach transforms the problem into pixel-level tracking of anomalous objects.
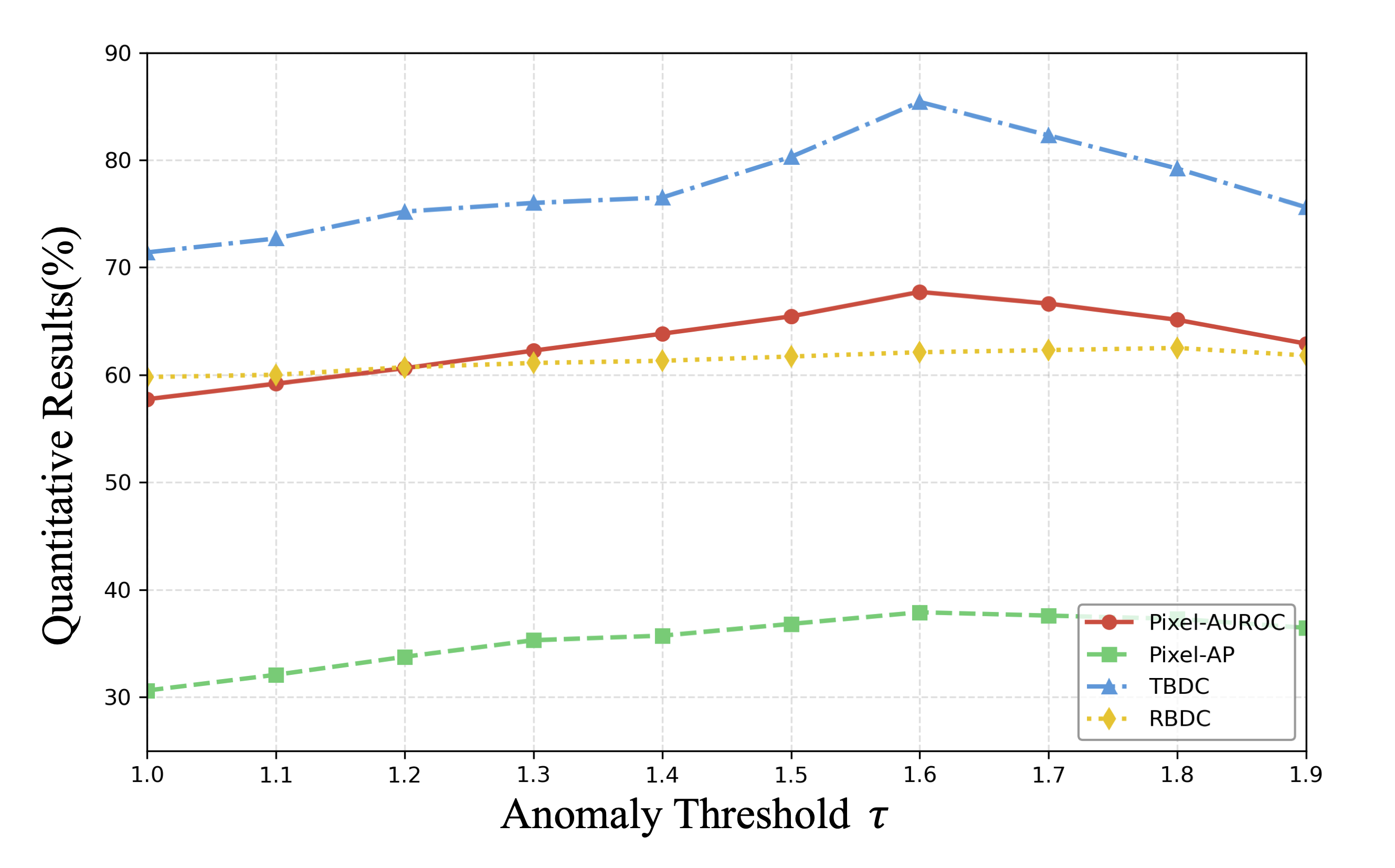
By linking anomaly scores to subsequent tasks such as image segmentation and video tracking, our method eliminates the need for threshold selection and achieves more precise anomaly localization,
even in longand challenging video sequences.
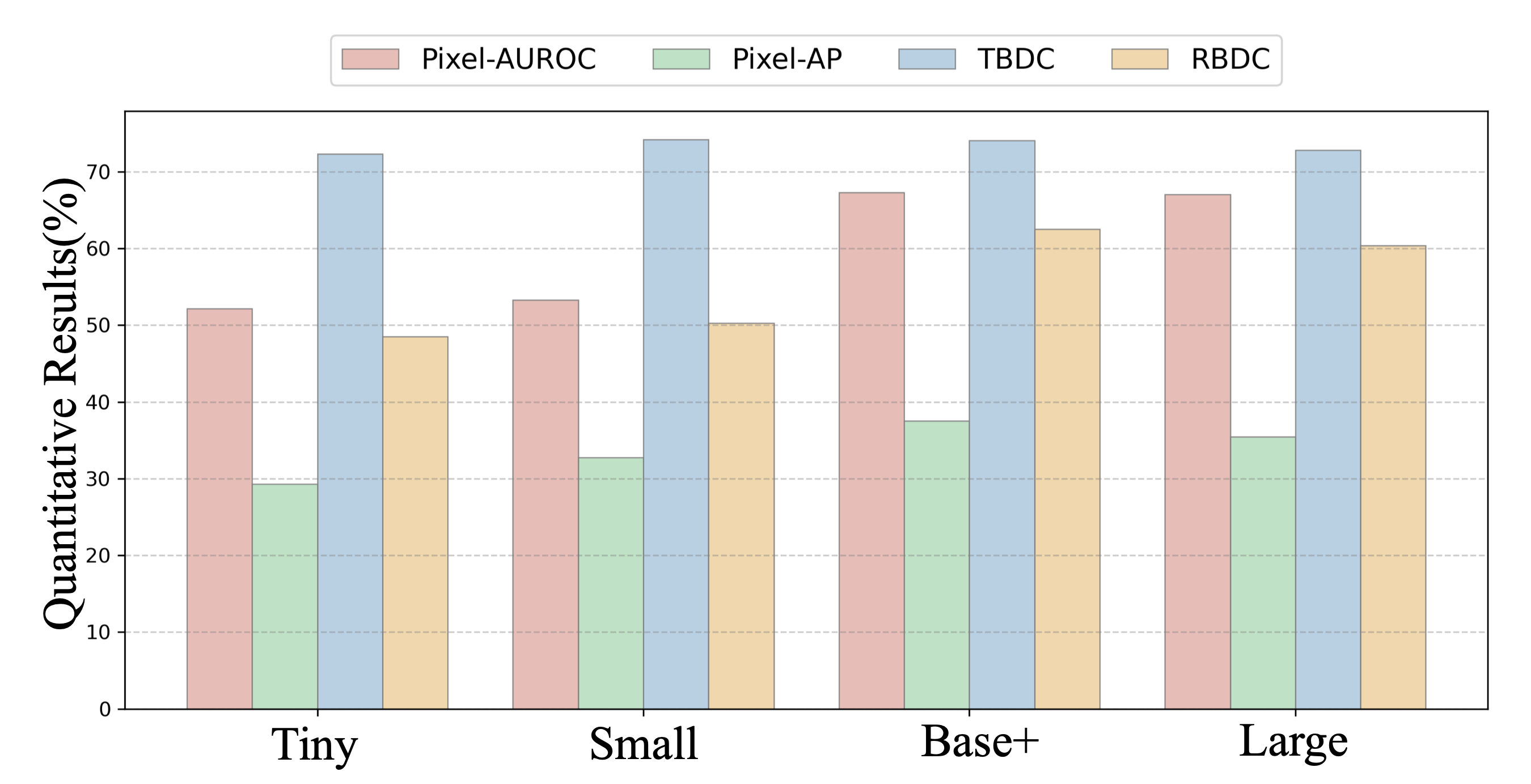
Experiments on extensive datasets demonstrate that TAO achieves state-of-the-art performance,
setting a new progress for VAD by providing a practical, granular, and holistic solution.